📊 Accepted at COLM 2025
BigCharts-R1: Enhanced Chart Reasoning with Visual Reinforcement Finetuning
Abstract
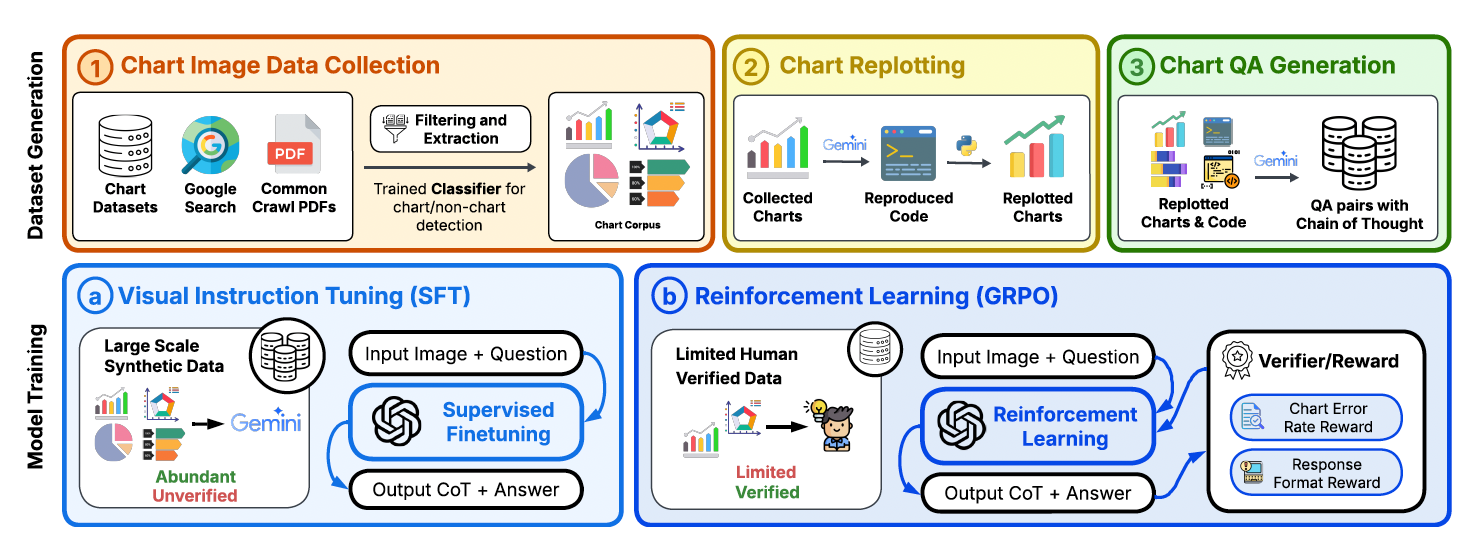
Chart comprehension is crucial for effective human decision-making, yet current vision-language models (VLMs) struggle with this task due to limitations in training data and methodologies. To address these challenges, we introduce BigCharts-R1, a state-of-the-art chart reasoning model, alongside a novel dataset and training framework.
- BigCharts Dataset. We propose a novel dataset creation pipeline, BigCharts, which generates visually diverse chart images by replotting real-world charts sourced from various online platforms. Unlike purely synthetic datasets, BigCharts maintains authenticity and visual diversity while ensuring accurate underlying data, overcoming the estimation errors often found in automatically extracted data tables.
- Comprehensive Training Framework:. Our approach integrates supervised fine-tuning (SFT) with Group Relative Policy Optimization (GRPO)-based reinforcement learning. We introduce novel reward signals specifically designed for chart reasoning, which significantly enhances model robustness and generalization across diverse chart styles and domains.
- State-of-the-Art Performance:. Extensive experiments demonstrate that BigCharts-R1 surpasses existing methods on multiple chart question-answering benchmarks, outperforming even larger open-source and closed-source models. This showcases BigCharts-R1's superior capabilities in chart reasoning.
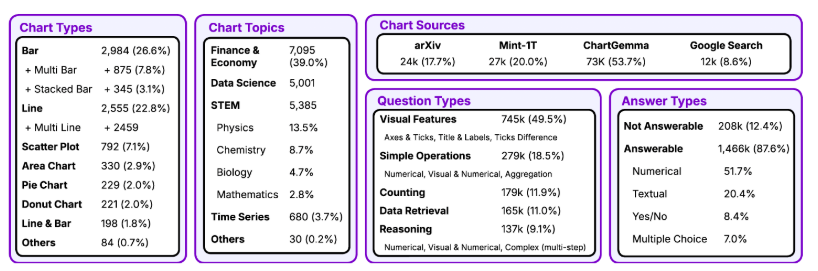
Dataset Statistics
Results
We evaluate BigCharts-R1 against state-of-the-art open-source and closed-source models across multiple chart question answering benchmarks. Our models demonstrate superior performance, particularly in the 3B and 7B parameter ranges.